


By Luay Al Assadi, Software Engineer.
Note: All the numbers mentioned in this blog post are not real and are used for illustrative purposes only.
At Toters Delivery it's very important to ensure that orders made by our customers are delivered by our delivery staff (called shoppers) in a timely manner. In order to continuously optimize our delivery operations, we store many details of shoppers' order fulfillment activities, including details about the reliability of their internet connection. This has been very important lately due to the unreliability of the internet in some of our major countries of operation.
Clearly this is a lot of data, and storing such vast amounts of data into our database is bound to affect query time. Enter: database partitioning.
Database Partitioning
Database partitioning refers to splitting the data into multiple tables and databases.It is generally done in a transparent way and the application will always deal with one logical table. In our case we will partition the shopper logs table in order to decrease the data volume that the DB engine scans each time we run a query, and that will help us in running commands in parallel and increasing performance. This is because using a sequential scan of a partition (small table) is better than using an index on a big table which would require random-access reads scattered across the whole table.
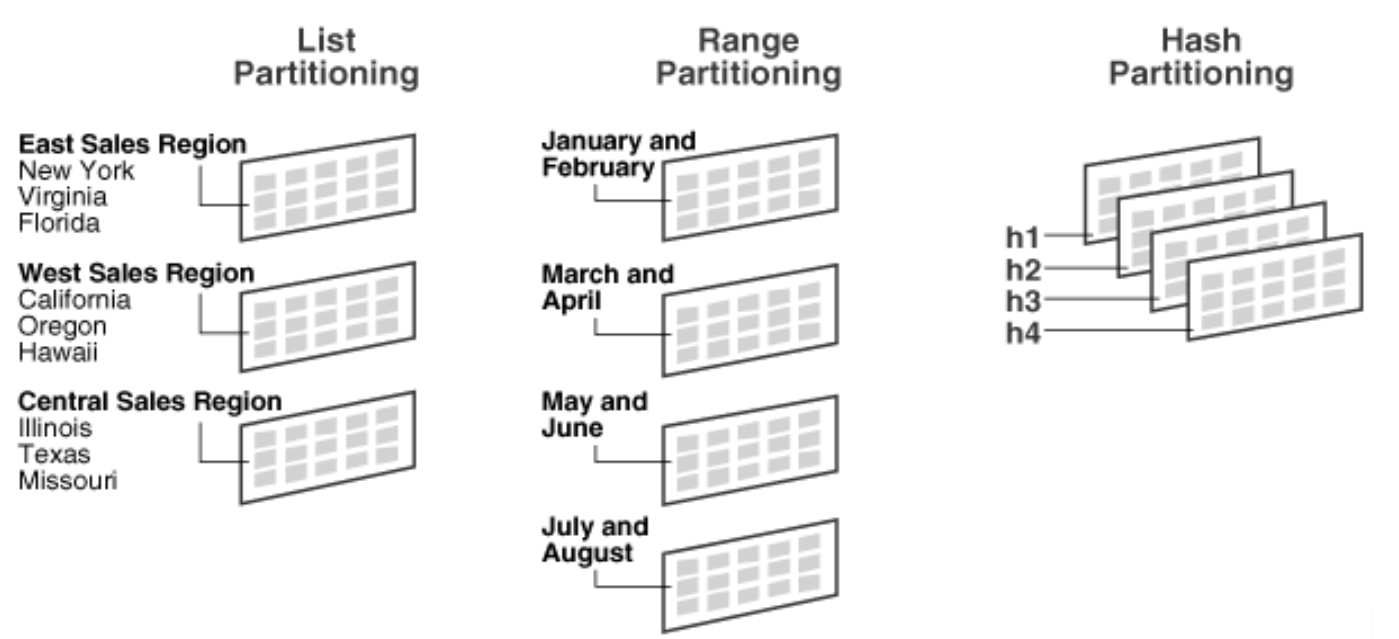
As we are using a PostgreSQL, we looked at the partitioning forms are offered by PostgreSQl and it offers the following:
Range Partitioning
The table is partitioned into “ranges” defined by a key column or set of columns, with no overlap between the ranges of values assigned to different partitions, and this approach is effective when we need to access the data by date, integer ranges.
List Partitioning
The table is partitioned by explicitly listing which key value(s) appear in each partition.
Hash Partitioning
The table is partitioned by specifying a modulus and a remainder for each partition. Each partition will hold the rows for which the hash value of the partition key divided by the specified modulus will produce the specified remainder.
Since most of our current SQL statements for accessing shopper logs table searches within time ranges, we decided to partition our table data by time intervals based on the date column using range partitioning. The following section will explain the analysis that helped us decide the time ranges for partitioning the table. The purpose was to save the execution plan time. Note: bad partitioning is worse than no partitioning.
Capacity Estimation and Constraints
Let’s assume that we have 1500 daily active shoppers and on average each shopper works 10 hours to accept delivering orders. This means we have 1500 X 10 X 60 X 2 = 1.8 million records per day.
Storage Estimation: Let’s assume that on average a record is 10 bytes, so to store all the logs for one day we would need 17MB of storage.
1.8 million records * 10 bytes => 17 MB/day
Then we need for 1 year:
17 * 365 => 6.3 GB/year
Let’s assume for the sake of argument that we grow at a rate of 150% shoppers a year. So if we want to provision enough database capacity for that for the next t years, we run our current numbers against the exponential growth formula:
x(t) = x₀ * (1 + r/100)ᵗ
we plug the numbers:
6.3 GB * (1+150/100)⁵ = 615 GB in 5 years
6.3 GB * (1+150/100)¹⁰ = 58.6 TB in 10 years
This means that we will be storing a massive amount of data in the next 5 years!
Shopper Logs Table Partitioning
Since Range partitioning form is the best choice to partition a table that is frequently scanned by a range predicate on a specific column such as date, we will partition this table schema into smaller tables based on the log record date. We will create a partition for every quarter, and the partition name will include the year and quarter it is made for like so:
shopper_logs_partitioned_child_{year}_{q}
And with this partitioning mechanism we will have about 200 partitions after 50 years, and regarding to PostgreSQL documentation this will not affect the query planning time
‘’Partitioning using these techniques will work well with up to perhaps a hundred partitions; don't try to use many thousands of partitions.’’
Continuing with our example, each partition size is 1.5 GB on average in the first year and will reach 92 GB after 5 years.
Shopper Logs Partitioning Performance
For this exercise we benchmarked the query performance of our existing table vs the partitioned table and got the following results:

We can clearly see the efficiency of using partitioning in our case [logging shopper locations]. Although the planning time is always more expensive in a partitioned table, we can see that the execution time is always less expensive. This happens because the DB engine takes longer in a partitioned table to decide which partitions should be used in a query. That said, the overall time spent for planning and executing queries are clearly much faster on a partitioned table compared to a non-partitioned one - a difference that grows even bigger as the size of the data increases.
That’s it! I hope you found this post useful. One of my own takeaways from this exercise is that while it’s fashionable for people to always jump at the latest technologies introduced by the infrastructure vendors out there (ie Dynamo DB or Aurora serverless by AWS, services which in some cases turn out to be sexy sounding but not exactly production ready) there is still a lot of tricks present in the legacy and less sexy technologies such as Postgresql!

